The Backend Magic Behind the Data Requests Template
How Scaler engineered auditable, portfolio-scale data collection without losing control of what gets written.
About Dejan and his work behind the scenes
My background is fintech and project-based engineering across domains that had nothing to do with sustainability. It took one collection season and one broken spreadsheet to show me that sustainability data had a bigger reliability problem than anything I'd seen before. Four years later, I'm still here because the problems are hard. GRESB, SFDR, net zero, each reporting framework has its own data requirements, and behind every requirement is a collection, validation, and governance challenge that someone has to solve in code.
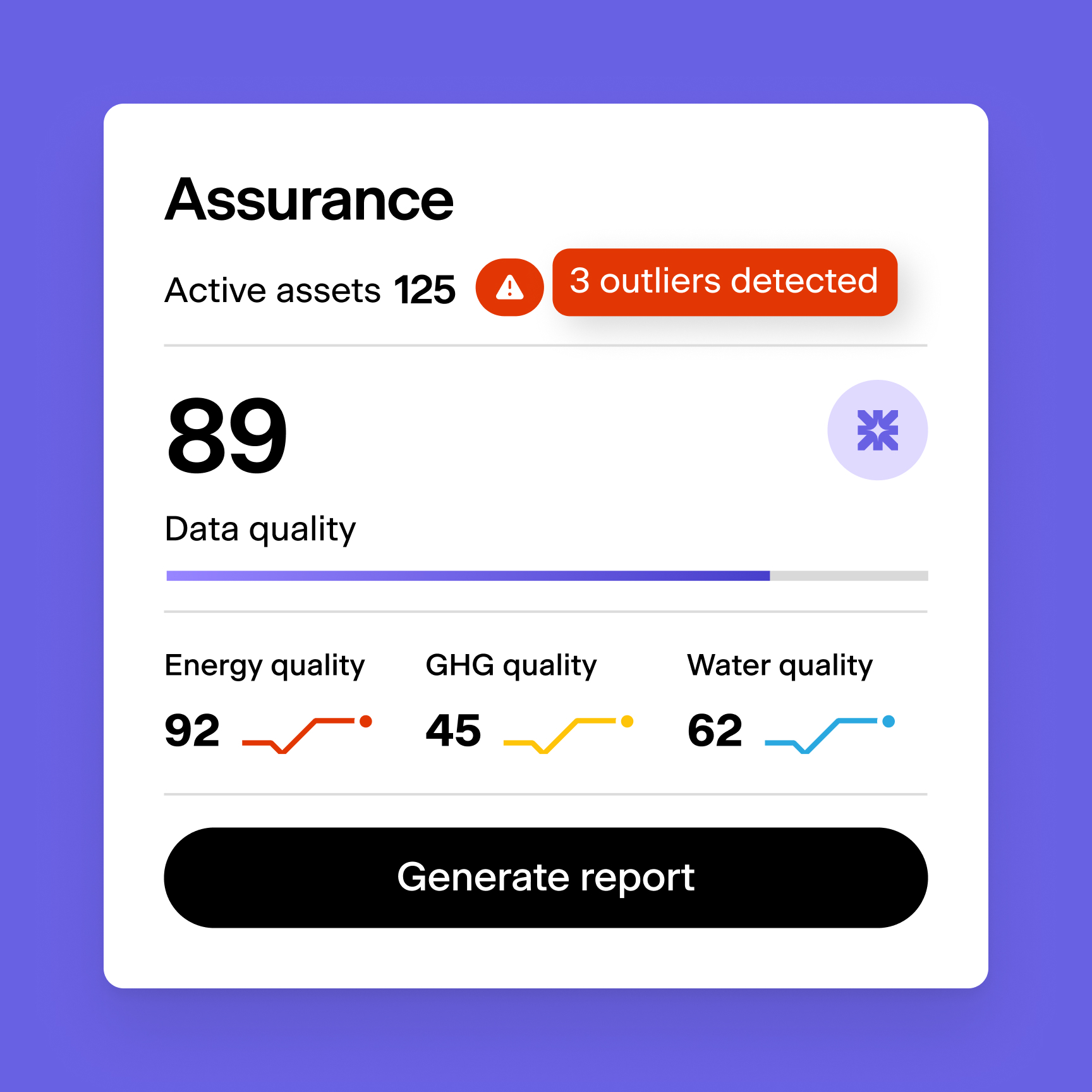
Getting the data in is only half the problem. The other half is making it trustworthy enough to visualise, benchmark, and act on. A single inconsistent meter reading can distort an entire portfolio's emissions baseline, and no dashboard can fix what was broken at the point of collection. Data Requests is how Scaler addresses that problem at the source.
Why traditional collection breaks down
Collecting sustainability data from dozens of external stakeholders, asset managers, tenants, service providers, typically means spreadsheets emailed back and forth and a review process built on trust rather than structure. One misplaced decimal, one overwritten cell, and the numbers flowing into your GRESB submission no longer trace back to a verifiable source.
Controlled collection at portfolio scale
Data requests lets an internal team member define exactly which data fields need updating, for which assets, and from whom. The system sends targeted invitations to external recipients, who fill in only the fields requested, through the platform or via Excel upload. Every submitted value lands in a staging area where reviewers can approve, reject, or flag changes at the individual field level before anything is committed to the live dataset. The outcome is clean, audited data collection at portfolio scale, with no uncontrolled writes.
How it works under the hood
The core engineering challenge was straightforward to define but complex to solve: let external users edit data in a form that looks and behaves like the real application, while ensuring nothing they submit can alter production data until explicitly approved. When a recipient opens their data request form, the system creates an isolated workspace, a sandboxed copy that merges a read-only snapshot of production data with any pending changes. From the recipient's perspective, they're editing a normal form. Behind the scenes, every change is captured as a structured diff (what changed, by whom, when) rather than applied to the live dataset.
The application's data layer detects these workspaces automatically and routes reads and writes through them, so all existing validation rules, calculations, and business logic work without a separate draft-mode codebase. When the recipient submits, a reviewer sees a side-by-side comparison of current and proposed values. Approval triggers a single atomic operation that migrates only the accepted changes into production, related records included, in the correct dependency order. If the operation fails at any point, nothing is partially applied. It either completes fully or not at all. Each data request operates in its own isolated workspace, so concurrent requests for different assets never interfere with each other.
Why it holds up at scale
Excel uploads and in-platform entries are validated against the same rule set before any change records are created. Formatting errors, constraint violations, and out-of-range values are caught at the boundary, not discovered during review. If a file contains problems, the recipient fixes and re-uploads without partial data leaking through. The atomic commit on approval guarantees that production data is never left in an inconsistent state, even if the operation is interrupted mid-write.
Built to grow with your portfolio
As your portfolio grows, data requests handle more assets, jurisdictions, and frameworks without requiring process changes on your end. What used to be a fragile, manual collection process becomes one that is auditable and repeatable at any scale.